Hopper/Blackwell Tensor Core MMA layouts
by Vijay Krishnamoorthy
Overview
This post explains shared memory (SMEM) matrix layouts for tcgen05 MMA instructions.
The main idea is that SMEM matrices are partitioned into contiguous “swizzle atoms” built from a smaller primitive called the core matrix. The SMEM descriptor then encodes the address, swizzle mode, and the strides between swizzle atoms.
While this post references Blackwell, all the concepts in this post are applicable to Hopper as well.
This post assumes some familiarity with GEMM kernels and dives right into a CTA/Threadblock’s tiled workload between its A and B matrix tiles in SMEM.
I’ll stick to fp16 as the dtype in this post, but everything discussed is applicable for other dtypes as well.
Code references
During Q4 last year, I spent some time writing an FP16 GEMM kernel for Blackwell in Cuda C++ and inline PTX, to better understand low level specifics.
As part of this effort, I implemented support for cta_group::2, TMA multicasting, warp specialization, persistent scheduling and multiple in-flight MMA tiles for pipelining with support for various MMA atom shapes.
Code referenced in this post are artifacts from this effort. (Github link)
Link to all the figures in this post
PTX Documentation
MMA layouts
Convention
Sticking with CuTe conventions, A matrix is always represented with shape (M,K) regardless of major ordering. Likewise, B matrix is represented with shape (N,K).
Strides in the layout are set in conformance with major ordering. For example with A matrix,
- M-major : (M,K):(1,M)
- K-major : (M,K):(K,1)
- coordinate (1,2) is M=1 and K=2 regardless of major ordering.
This is important so you don’t get things mixed up as you read the rest of this post.
Key Primitives
-
MMA atom tiles
-
An MMA atom tile is the tile extent consumed by the MMA instruction. For example, fp16 tcgen05 mma instruction with kM = 128 and kN = 256, has (128,16) as its MMA atom tile shape for A, and (256,16) as its MMA atom tile shape for B. It’s worth noting that K for dense mma instructions is fixed at 32 bytes (i.e. 16 fp16 elements).
-
The figure below shows MMA atom tiles in A, B and C with this MMA instruction.
-
Given the MMA instruction has an output shape of (128, 256), its extents cover half of the output tile that is (256,256).
-
Further, we need 4 mma instructions with offsets in increment of 16 elements, along K. This is because the mma instruction’s K is limited to 16 elements, but we need to do a contraction across the full span of 64 elements along K.
-
This would mean each output sub-tile of shape (128,256) in C would require 4 MMA instructions, i.e. a total of 8 MMA instructions to cover the entire (256, 256) output tile.
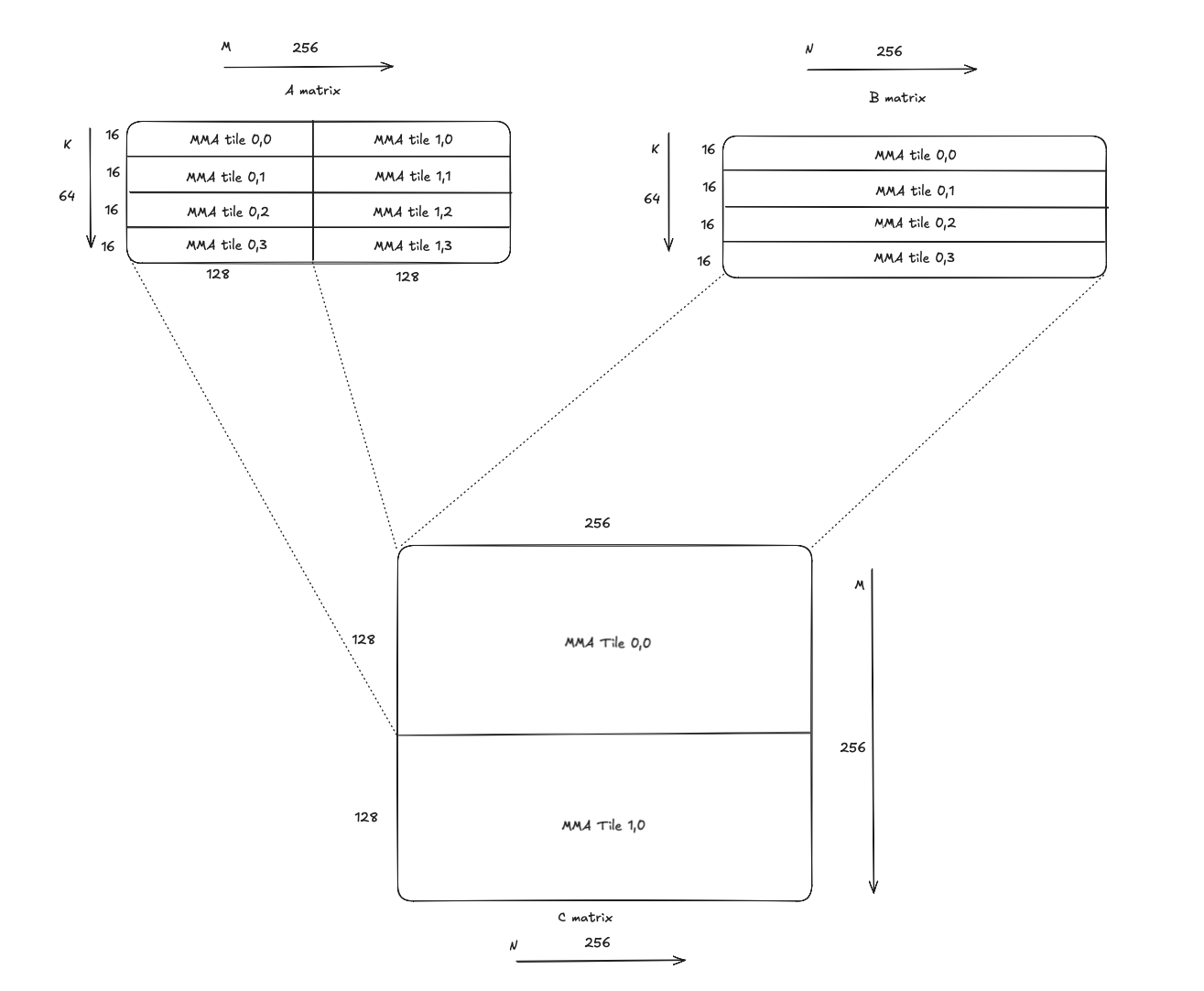 Figure: MMA atom tiles.
Figure: MMA atom tiles. -
-
Core matrix (smallest primitive)
- Always 8 x 16B in shape, 8 rows, each 16 bytes wide.
- In fp16, that is 8 rows x 8 elements per row (16B / 2B).
- This lines up with one row of SMEM banks (32 banks x 4B = 128B), i.e a core matrix if stored contiguously in SMEM would result in no bank conflicts.
- In general, being able to load/store a core matrix worth of data per clock would mean peak SMEM bandwidth utilization.
- However, using skinny swizzle atoms will result in poor cache utilization when loading tiles from DRAM. More on this in a future post.
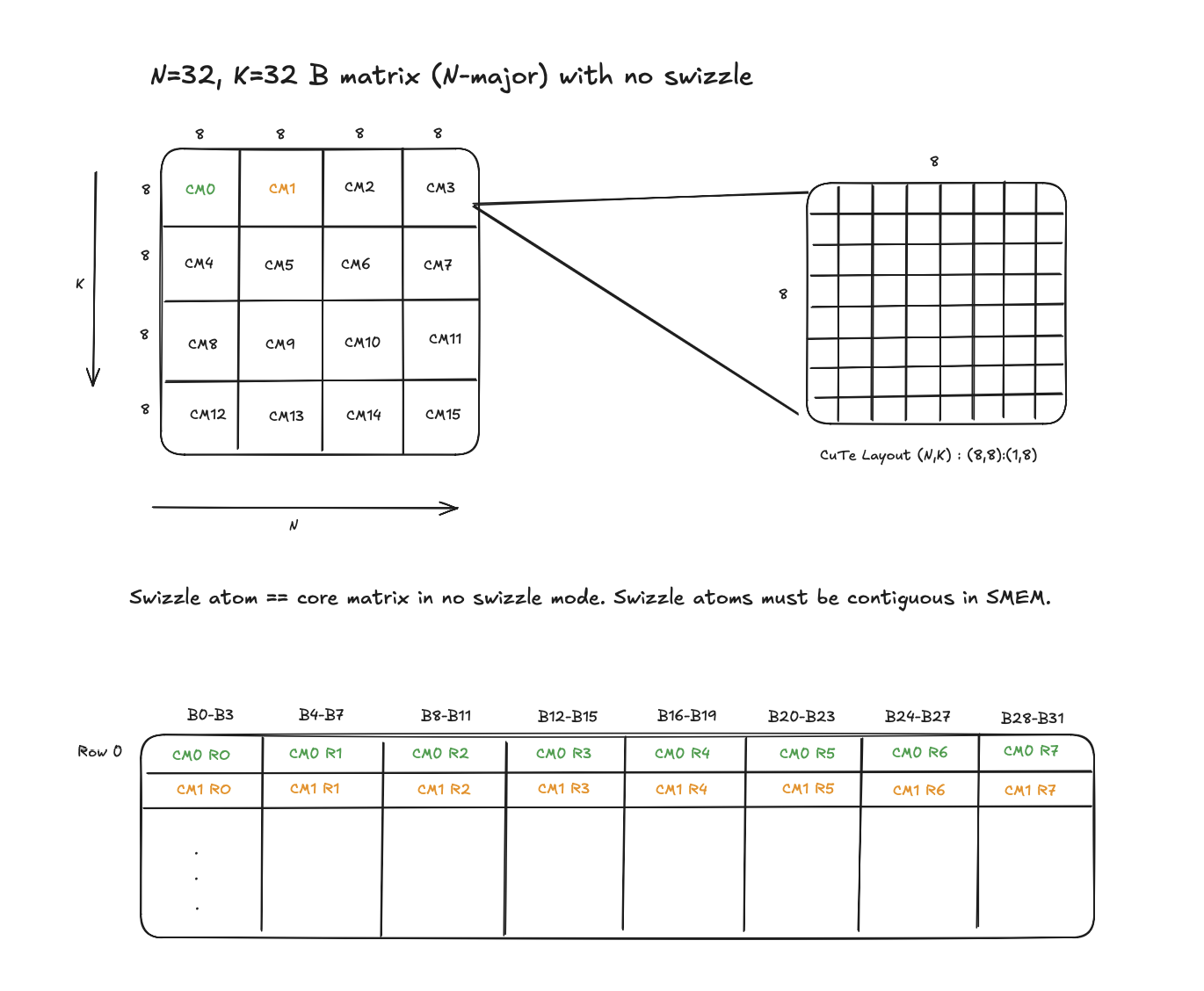 Figure: Core Matrices in SMEM tile.
Figure: Core Matrices in SMEM tile. -
Swizzle atom (layout unit for SMEM matrices)
- Always 8 rows tall, width depends on swizzle mode.
- Contiguous in SMEM.
- If no swizzle is enabled, the swizzle atom is exactly one core matrix, 16B wide.
- If swizzle is enabled, a swizzle atom is 2, 4, or 8 core matrices wide (32B, 64B, or 128B wide).
- Granularity of swizzle is typically 16 bytes (4 SMEM banks). Blackwell also supports 128B swizzle atom with 32 byte swizzle units.
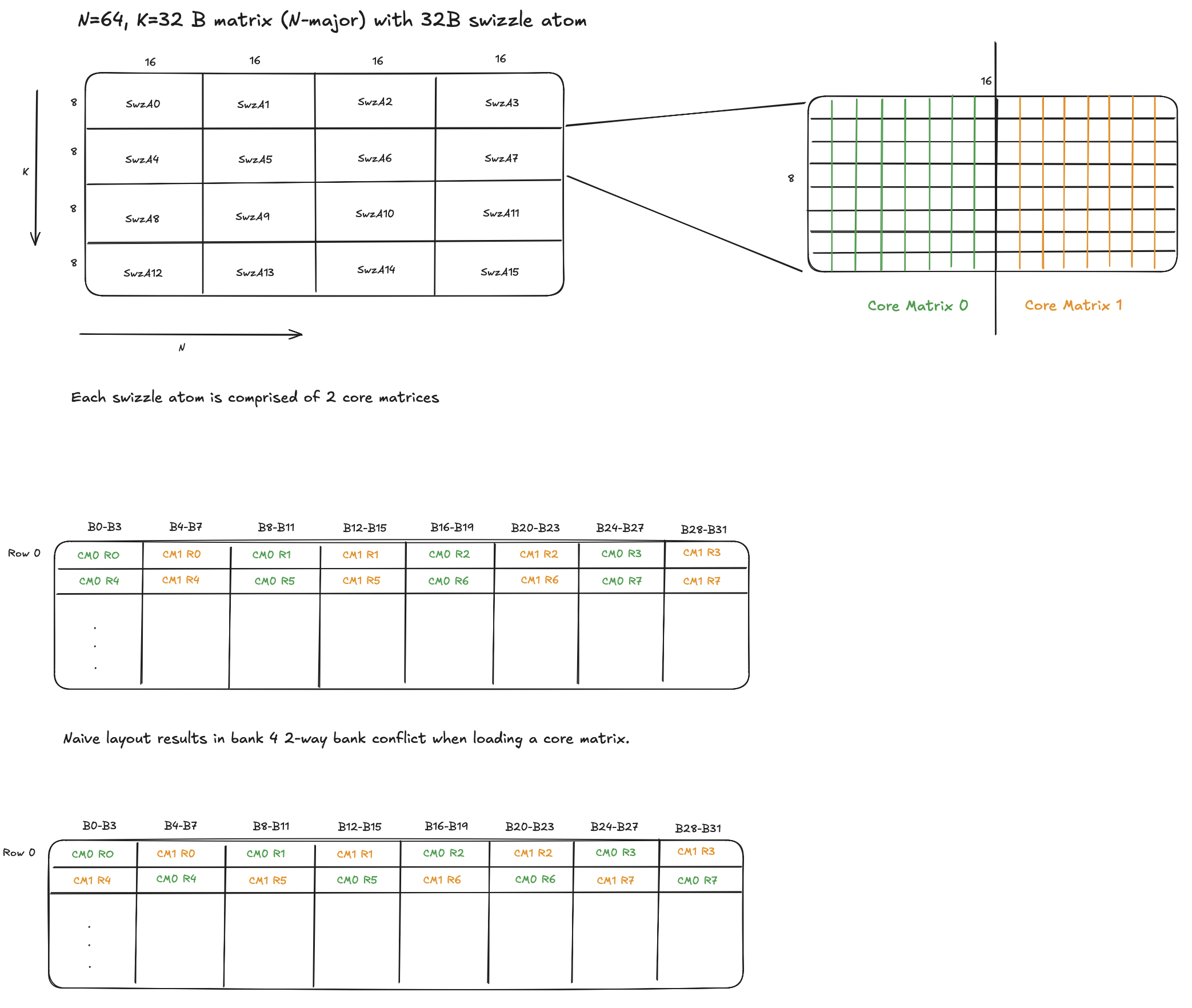 Figure: 32B Swizzle Atom with 2 core matrices.
Figure: 32B Swizzle Atom with 2 core matrices.
The figure above, shows the logical view as well as physical organization of a (64,32) N-major matrix with 32B swizzle atoms. Note that, the naive SMEM layout won’t work with MMA instructions (i.e. won’t produce correct results). I’ve added it for illustration purposes only.
To summarize, here’s a hierarchical view -
- An SMEM tile is composed of one or more MMA atom tiles.
- An MMA atom tile is composed of one or more swizzle atoms.
- A swizzle atom is composed of 1,2,4 or 8 core matrices.
MMA instructions use Leading Byte offset and Strided Byte offset to get to next swizzle atom along either axis. More on this in the next section.
Smem Descriptor
SmemDesc packs the SMEM address, swizzle, and strides into bitfields:
Addr:base address (SMEM pointer)LBO:leading byte offset (stride between swizzle atoms on the major axis)SBO:strided byte offset (stride between swizzle atoms on the minor axis)MBO:matrix byte offset (derived from address and swizzle)LDM:leading dimension stride mode (set to 0 in current kernels)SM:swizzle mode
tcgen05 instruction takes the underlying 64-bit value of the SMEM descriptor for A and B matrices. A can also be resident in TMEM, in which case there’s no need for an SMEM descriptor.
Leading Byte Offset (LBO) and Strided Byte Offset (SBO) are used by the MMA instruction when the MMA atom tile has multiple swizzle atoms. They represent the stride in bytes from one swizzle atom to the next along the contiguous/major axis and non-contiguous/minor axis respectively.
Interpretation:
- LBO is the stride between swizzle atoms along the major axis.
- SBO is the stride between swizzle atoms along the minor axis.
- The one exception to this rule is when swizzle is disabled with M/N-major layouts. The programmed values are swapped, i.e. stride along major axis is set as SBO and stride along minor axis is set as LBO.
In SmemDesc, LBO and SBO are encoded in 16-byte units (see the encode/decode
logic in gsopt/cuda_ptx/ptx/tcgen05/smem_desc.cuh). The printed “actual” value
is computed by shifting the stored field left by 4, i.e. multiply by 16.
For example with M/N-major:
constexpr uint32_t swz_atom_width_in_bytes = SwizzleAtomWidthInBytes(swizzle);
constexpr uint32_t swz_atom_height = 8;
constexpr uint32_t swz_atom_size_in_bytes =
swz_atom_height * swz_atom_width_in_bytes;
constexpr uint32_t num_swz_atoms_along_M =
bM / (swz_atom_width_in_bytes / sizeof(__half));
constexpr uint32_t lbo =
(swizzle == ptx::SwizzleMode::kNoSwizzle)
? swz_atom_size_in_bytes * num_swz_atoms_along_M
: swz_atom_size_in_bytes;
constexpr uint32_t sbo =
(swizzle == ptx::SwizzleMode::kNoSwizzle)
? swz_atom_size_in_bytes
: swz_atom_size_in_bytes * num_swz_atoms_along_M;
I also have a simple example kernel for K-major, here.
If the MMA atom tile address doesn’t align with the size of the swizzle atom, i.e. 256B/512B/1024B for 32B/64B/128B swizzle atoms, matrix byte offset is non-zero and must be set to the offset from the aligned address boundary. From the PTX doc,
base offset = (pattern start addr >> 0x7) & 0x7;
Examples
Let’s walk through a few examples with M/N-major and K-major.
1. Fp16 M-major matrix with 128B swizzle atom.
The figure below shows an M-major A matrix tile in SMEM with 2 MMA atom tiles along M and 4 MMA atom tiles along K.
Each MMA atom tile has the shape (128,16) and has (2,2) 128B swizzle atoms each with a shape of (64,8).
Assuming swizzle atoms along M are stored first in shared memory when loading from DRAM,
-
LBO = size of swizzle atom (8 * 64 = 512 elements / 1024 bytes)
-
SBO = size of swizzle atom * number of swizzle atoms along M = 8 * 64 * 4 = 2048 elements / 4096 bytes
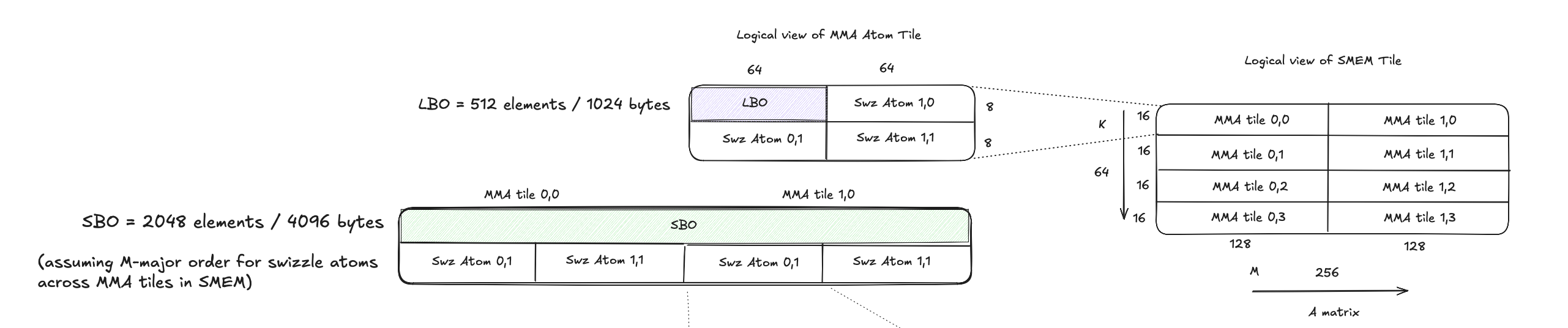 Figure: M-major matrix with 128B Swizzle Atom.
Figure: M-major matrix with 128B Swizzle Atom.
Bank conflict free SMEM organization for each swizzle atom -
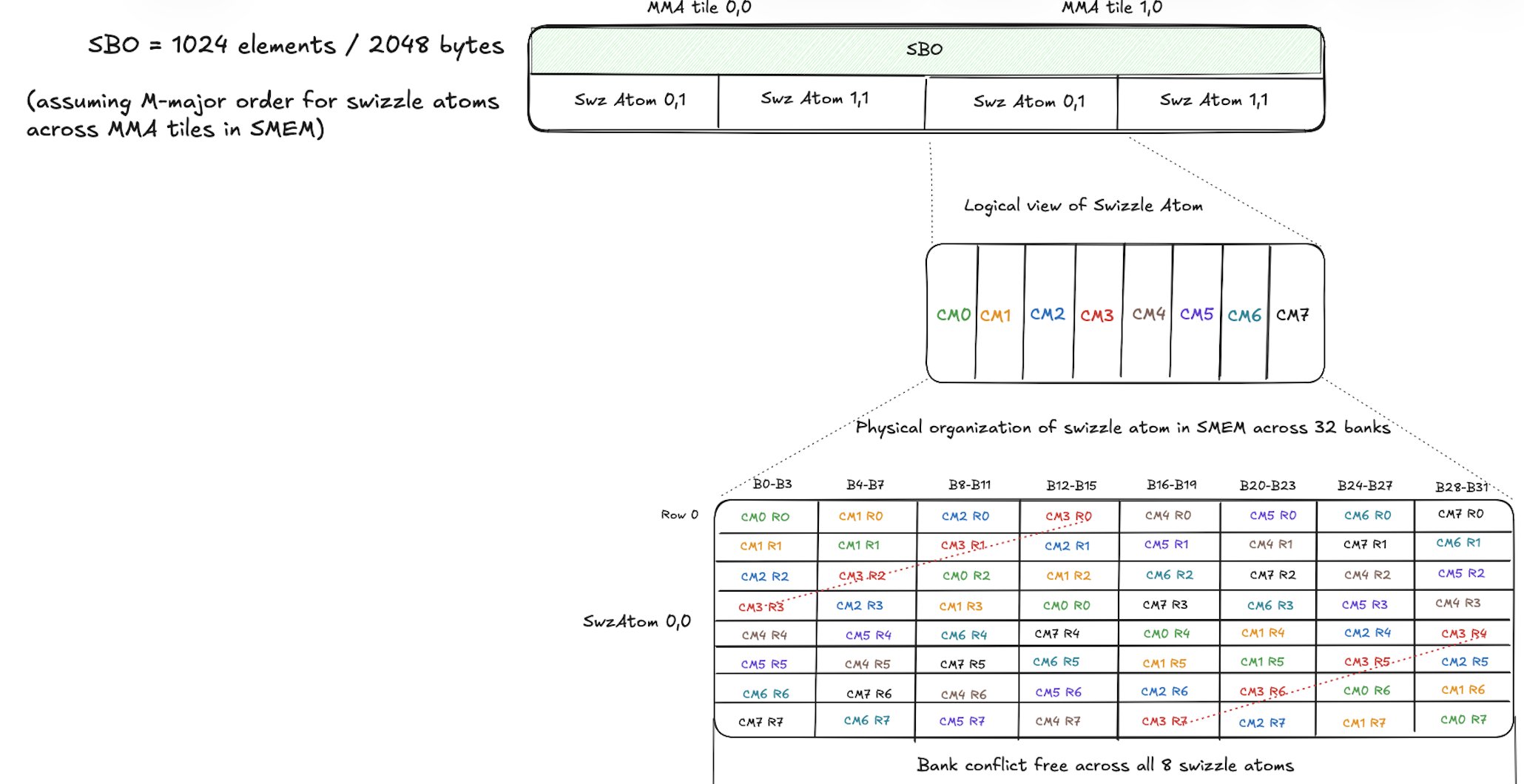 Figure: M-major matrix with 128B Swizzle Atom.
Figure: M-major matrix with 128B Swizzle Atom.
2. Fp16 K-major matrix with no swizzle
The figure below shows a K-major A matrix tile in SMEM with 2 MMA atom tiles along M and 4 MMA atom tiles along K.
Each MMA atom tile has the shape (128,16) with (16,2) swizzle atoms in no-swizzle mode (i.e. core matrices), each with a shape of (8,8).
Assuming swizzle atoms along K are stored first in shared memory when loading from DRAM,
-
LBO = size of swizzle atom (8 * 8 = 64 elements / 128 bytes)
-
SBO = size of swizzle atom * number of swizzle atoms along K = 8 * 8 * 8 = 512 elements / 1024 bytes
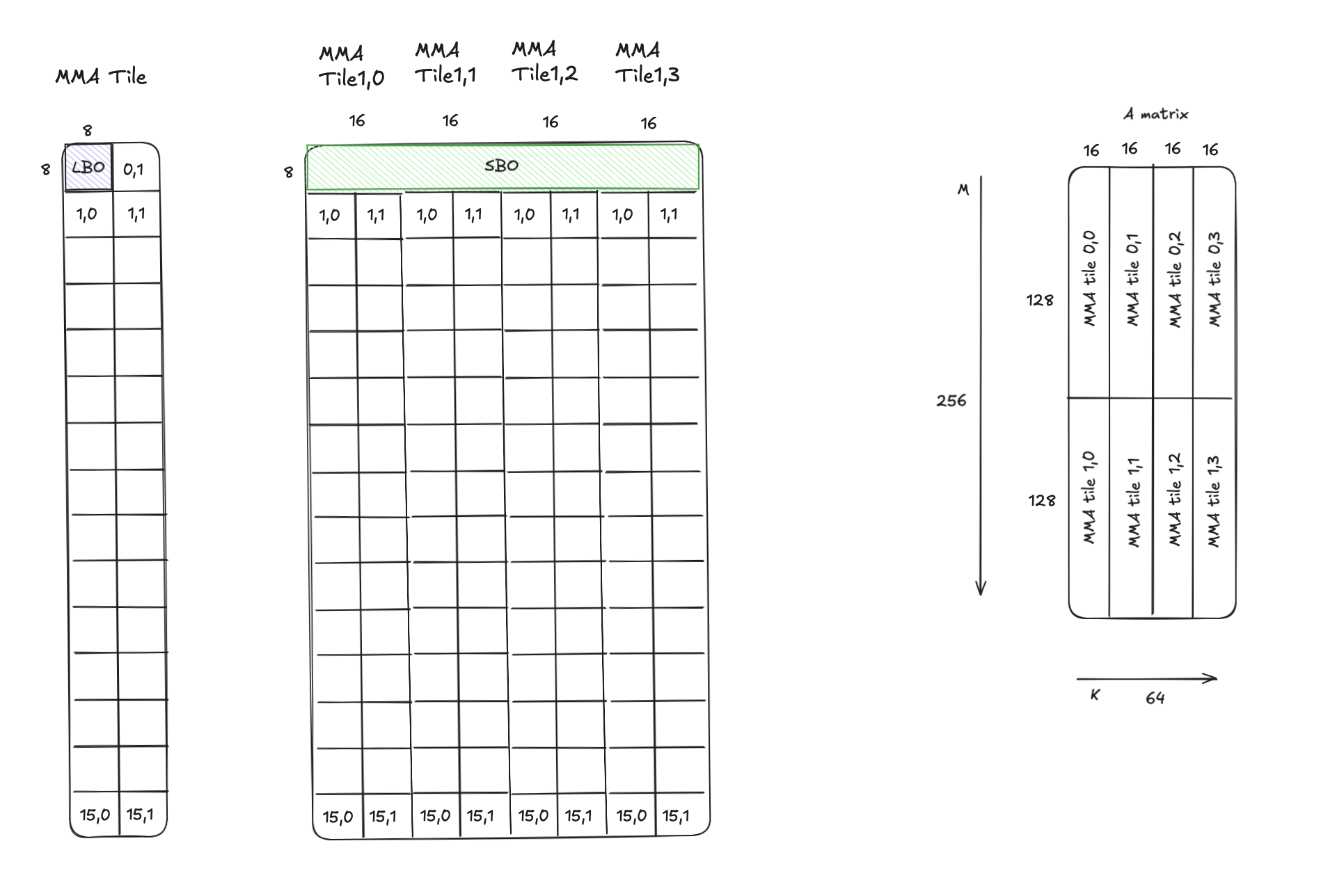 Figure: K-major matrix with Swizzle Atoms in no swizzle mode.
Figure: K-major matrix with Swizzle Atoms in no swizzle mode.
3. Fp16 K-major matrix with 32B swizzle
The figure below shows a K-major A matrix tile in SMEM with 2 MMA atom tiles along M and 4 MMA atom tiles along K.
Each MMA atom tile has the shape (128,16) with (16,1) swizzle atoms in 32B swizzle mode, each with a shape of (16,8).
Assuming swizzle atoms along K are stored first in shared memory when loading from DRAM,
-
LBO is unused, since K extent for an MMA atom is 32B (16 elements). Hence an MMA atom tile doesn’t transcend a swizzle atom along K dim. Naturally, this is also applicable for 64B and 128B swizzle atoms.
-
SBO = size of swizzle atom * number of swizzle atoms along K = 8 * 16 * 4 = 512 elements / 1024 bytes
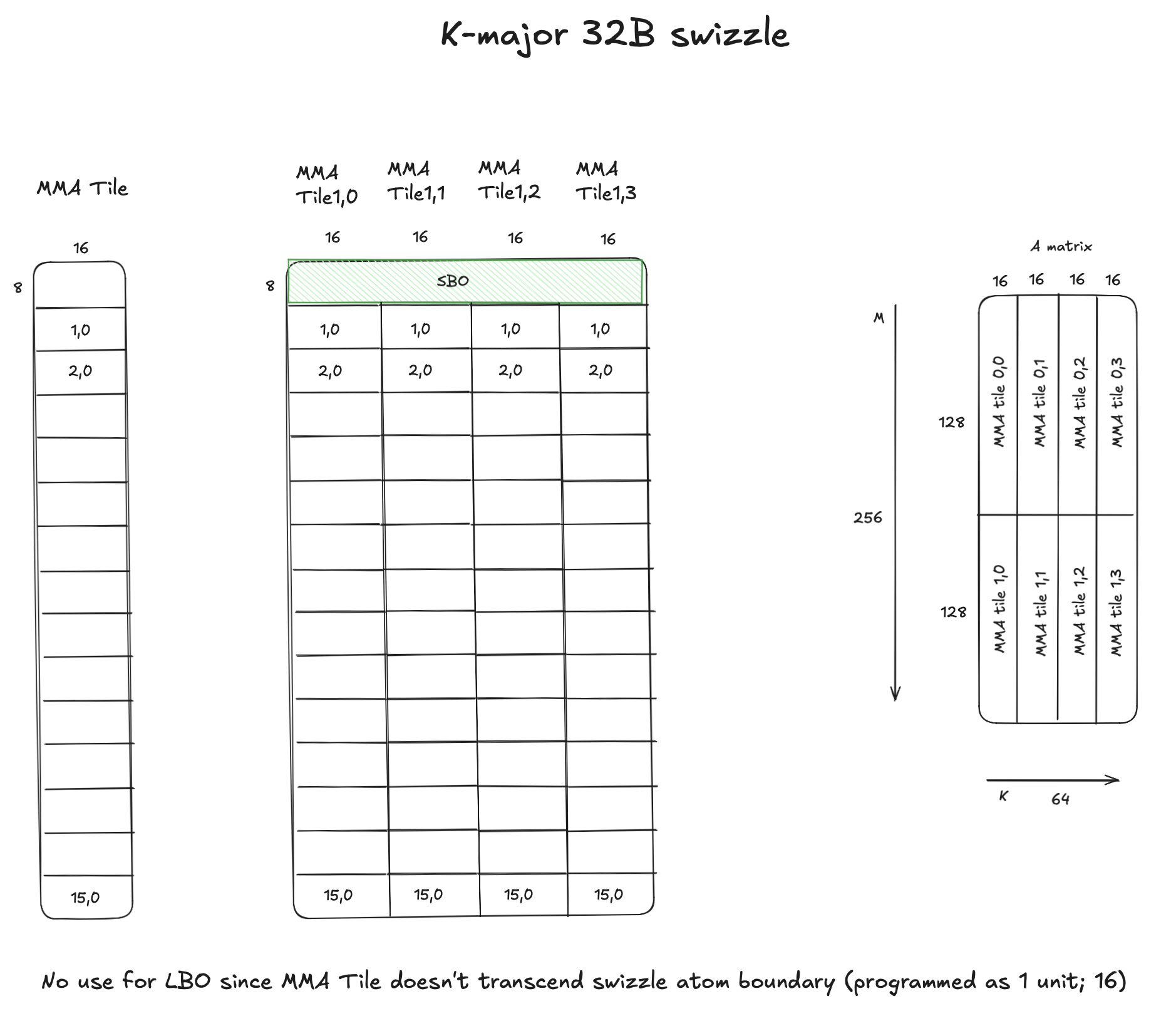 Figure: K-major matrix with 32B Swizzle Atoms.
Figure: K-major matrix with 32B Swizzle Atoms.
Conclusion
Hopefully this helps clarify specifics around MMA layouts which I believe is somewhat less understood. Please let me know if you spot any inaccuracies.
In future posts, I plan on delving into TMA programming, cta_group::2 mode, TMA multicast, TMEM specifics.
I also spent a few months last year authoring some kernels for AMD MI3xx and intend to write up posts on AMD GPUs as well.